

DF-Platter is a novel DeepFake dataset comprising 133,260 videos generated using three different generation techniques. It is one of the first large-scale datasets which incorporates the concept of Multi-subject deepfakes which implies having more than one deepfake subject in one frame of a video. Previous works have utilized a synthetically generated target image for multi-subject deepfake generation, whereas we have utilized both real source and target videos. We generate these multi-subject deepfakes by using the subjects present in a single video wherein some are considered as sources and others as targets. Such videos are termed as intra-deepfakes. Our dataset comprises a set focussed on celebrities wherein videos of celebrities are used as targets.
The subjects in this dataset are of Indian ethnicity, which is done to offset the lack of Indian ethnicity deepfakes in existing works. This abject lack of Indian ethnicity deepfakes results in a bias towards such samples and an increased proneness of misclassification for models trained on such datasets. Also, we generate inherently low-resolution deepfakes, which are found to be better in visual quality than synthetically generated low-resolution deepfakes (C23 and C40 compressed videos). Furthermore, the subjects in the dataset are richly annotated on various attributes like Age, Gender, Skin color, and Facial occlusion. We have maintained the gender ratio to be approximately 50-50. We also provide comprehensive benchmarks for different detection models employing varied evaluation protocols.
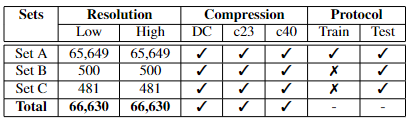
Summarizing the details of the DF-Platter dataset. DC - Default YouTube compression
The DF-Platter dataset is around 500GB in its raw form. It contains a total of 133,260 videos wherein each video is approximately 20 seconds in duration. Set A is the largest subset in the dataset with 130,696 deepfake videos. Set B and Set C contain 900 deepfake videos each. The videos are made available in MPEG4.0 format with high-resolution as well as its corresponding low-resolution. All videos have 25 frames per second. The dataset is consistent in terms of number of videos across resolution, gender of the subject and the generation technique utilized. For compression, H.264 video compression is utilized.
Df-Platter dataset
(c0.zip, md5sum - dc415c3865b4e442eafa3e2ee14fc703, crc32 - 5bca7308)
c23.zip, md5sum - 55e1b1147fb3c014164f83c6194ab1b6, crc32 - 3f4a9e42
c40.zip, md5sum - e8128644446ef738e877f5c86f426b57, crc32 - 8437c98f)
DF-Platter is annotated with varied attributes like gender, resolution, occlusion, and skin tone. Gender has been annotated for two classes - Male or Female. The skin tone is annotated on a scale of 1 to 6 for each subject using the Fitzpatrick scale}. The skin tone annotations are measured in fitzpatrick scale and then verified by a human annotator. The age attribute is classified into three classes - Young Adult (subjects with evident age between 18 to 30 years), Adult (subjects with evident age between 30 to 55 years), and Old (subjects with evident age above 55 years). Annotations related to facial occlusion are annotated into eight broad categories notably: 5'o'clock shadow, Beard, Moustache, Spectacles, Shades, Microphone, Cap/Turban/Hijab/Scarf, and Hair Occlusion. These attributes are binary in nature with "Y" indicating their presence and "N" indicating their absence. The number of male and female subjects in Set A are 151 and 150 respectively. Similarly, Set C comprises 15 male and 16 female subjects in the single-subject subset. In terms of age demographics, 51.33% of subjects are classified as "Young Adult", 42% of subjects are "Adult" and 6.66% of subjects are "Old". Moustache and Beard were the most common type of occlusion in males with around 90% of subjects having them.
Task of Deepfake Detection wherein all models are trained and tested on the same datasets
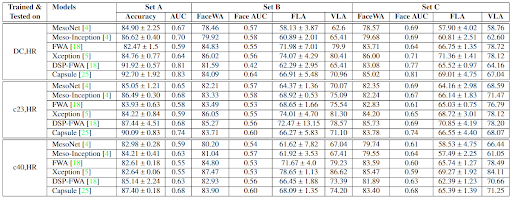
Task of Deepfake Detection in a cross-subset setting wherein all models are trained on high-resolution youtube compressed videos and tested on its low-resolution versions


The file naming of the videos is organized so that the source and target videos can be identified:
Set A →
x_y.mp4: Here x is the target video and y is the source video. It means that the background will be from video x and the subject's face will be from video y.
Set B →
x_yz.mp4: Here x is the video number and y,z are indices of the faces in the frame. The face indexing starts from 0 and the left most face in the frame is assigned 0. x_yz implies that x is the video in which the face z is pasted over face y.
Set C →
x_yz_ab.mp4: Here a,b are also indices of faces in the frame. The above naming convention can be extended in this case. Here the face have been swapped twice. Face z is pasted over face y and face b is pasted over face a.
x__y_z__a_b.mp4: Here y and b both are indices of faces in the frame. The above naming convention can be extended in this case. Here the faces have been swapped twice. Face in video z is pasted over face y and face in video b is pasted over face a.
License Agreement + Citation