
Deepfake and Spoofing
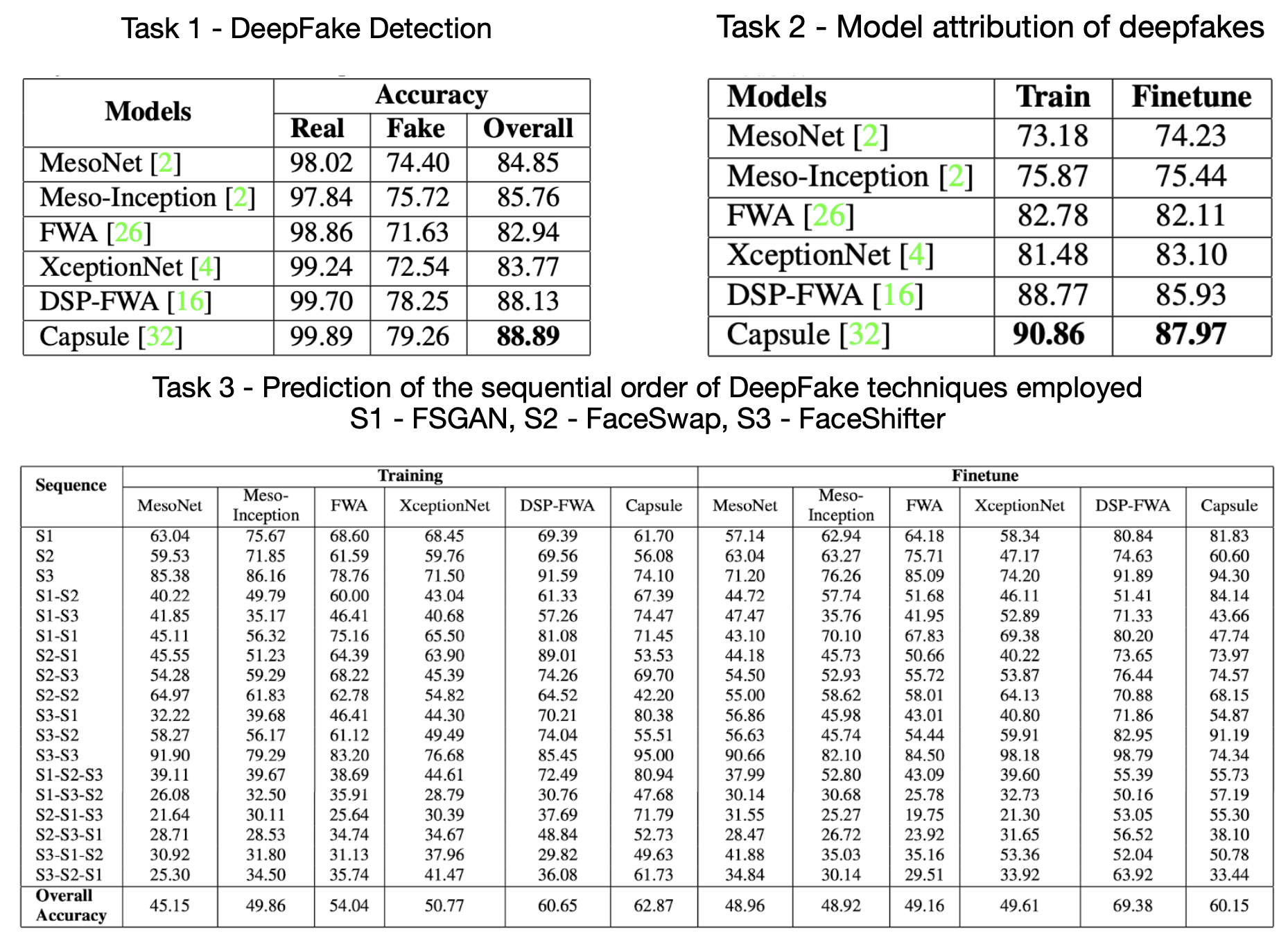
DF-Platter is a novel DeepFake dataset comprising 133,260 videos generated using three different generation techniques. It is one of the first large-scale datasets which incorporates the concept of Multi-subject deepfakes which implies having more than one deepfake subject in one frame of a video. The database can be downloaded from here.
DeePhy is a novel DeepFake Phylogeny dataset consisting of 5040 DeepFake videos generated using three different generation techniques. It is one of the first datasets which incorporates the concept of Deepfake Phylogeny which refers to the idea of generation of DeepFakes using multiple generation techniques in a sequential manner.
The dataset can be used for the tasks of (i) DeepFake Detection ,(ii) Model Attribution of DeepFakes and (iii) Prediction of the sequential order of DeepFake techniques employed to create phylogenetic deepfakes. It will facilitate advancements in real-life scenarios of plagiarism detection, forgery detection, and reverse engineering of deepfakes.
Dataset Statistics/Size/Format
The dataset consists of 100 real videos and 5040 DeepFake videos generated using several iterations of face swapping. There are 840 videos of one-time swapped deepfakes (Iteration 1 deepfakes), 2520 videos of two-times swapped deepfakes (Iteration 2 deepfakes) and 1680 videos of three-times swapped deepfakes (Iteration 3 deepfakes). The total raw size of the dataset is approximately 30 GB. The average duration of the videos is approximately 20 seconds and all videos are in 720p resolution with 25 frames per second. The videos are in MPEG4.0 format.
Deephy dataset (CRC32: 4977e5c7, MD5: 9c47fe0b5ee291392ed43edf69d245e3)
Dataset Annotations
The real videos of subjects are taken from Youtube which is a publicly accessible platform with diverse distribution in gender, orientation, skin tone, size of face (in pixels), lighting conditions, background and presence of occlusion. DeepPhy dataset is annotated with 10 attributes - Gender, Age, Skin Color, 5oClockshadow, Beard, Moustache, Spectacles, Shades, Mic, Cap/Turban/Hijab/Scarf and Hair Occlusion. Gender is annotated as “Male” or “Female”. Age is divided into three categories, people with apparent age between 18 (inclusive) to 30 belong to “Young Adult”, with apparent age between 30 (inclusive) to 55 belong to “Adult” and with apparent age greater than 55 (inclusive) belong to “Old”. The Skin Color annotations vary from 1 to 6 which corresponds to the 6 skin color types in the Fitzpatrick scale. All the other attributes are binary and their values can either be “Y” or “N” which represents presence of the attribute and absence of the attribute, respectively.
Dataset Benchmarking
Dataset Samples

Dataset Directory Structure and File Naming
- – fake
- – iteration 1
- – faceshifter
- – female
- – male
- – faceswap
- – fsgan
- – faceshifter
- – iteration 2
- – faceshifter_faceshifter
- – faceshifter_faceswap
- – faceshifter_fsgan
- – faceswap_faceshifter
- – faceswap_faceswap
- – faceswap_fsgan
- – fsgan_faceshifter
- – fsgan_faceswap
- – fsgan_fsgan
- – iteration 3
- – faceshifter_faceswap_fsgan
- – faceshifter_fsgan_faceswap
- – faceswap_faceshifter_fsgan
- – faceswap_fsgan_faceshifter
- – fsgan_faceshifter_faceswap
- – fsgan_faceswap_faceshifter
- – real
- – female
- – male
The file naming of the videos are organized so that the source and target videos can be identified.
Iteration 1 →
x_y.mp4. Here x is the target video and y is the source video. It means that the background will be of video x and the face will be of video y.
Iteration 2 →
x_y_z.mp4. Here x is the target video and y, z are the source videos. It means that the background will be of video x and the face will be of video y over which another face of video z will be pasted.
Iteration 3 →
x_y_z_w.mp4. Here x is the target video and y, z, w are the source videos. It means that the background will be of video x and the faces will be pasted in the order y - z - w.
License Agreement + Citation
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for DeePhy”
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - K. Narayan, H. Agarwal, K.Thakral, S. Mittal, M. Vatsa, and R. Singh, DeePhy: On DeepFake Phylogeny, International Joint Conference on Biometrics, 2022 (IJCB - 2022).
The MLFP database [1] contains the real and mask attack videos in visible, near-infrared, thermal spectrum. The database contains 1,350 videos in total, out of which 1,200 videos are attack videos and 150 videos are real access videos. The database consists of 10 subjects (4 females and 6 males) between the age of 23-38 years.
The real access videos are captured in different sessions at two different locations: Indoor and Outdoor of office. The videos are captured in all three spectrums: Visible, Near-Infrared, and Thermal. For each subject 4 real access videos are captured which represents two locations and two sessions. In total, database contains 40 videos of 10 subjects in each spectrum. Other than this one more real access video is captured for each subject for face identification experiments, which is not used for presentation attack detection.
Collection of Mask Attack Videos:
In the MLFP database, two types of face masks are utilized:
- 3D Latex Masks: Seven different latex masks are used for attack videos collection. These masks allow life-like movement of mouth as well as face. While six masks cover the entire face, the seventh mask is a half-mask which covers the face region below the eyes.
- 2D Paper Masks: Three paper masks are utilized with cutouts for eyes. These are created using high resolution images on high quality card paper.
The directory structure for VIS spectrum:
VIS--> Session (1 and 2) --> Environment folder (Indoor and Outdoor) --> Subject folders ( 1 to 10) --> Type of Videos (10 mask attack and 1 real). Folder name M represents the mask attack videos and R represents the real video. For each subject, there are 4 real and 40 mask attack videos per spectrum in the database. Each spectrum follows the same directory structure.
Database Protocol:
The MLFP database contains videos from 10 subjects wearing 10 different masks. The database is divided both based on subject and masks unseen training-testing protocol. For example, for one fold 3 random subjects are selected where each subjects 10 mask videos are there, out of these 9 (because the tenth mask which is unique as it is a half mask, is always utilized in the testing set) you randomly chose one paper mask and two latex masks in the training fold of these 3 subjects while the remaining unseen masks are utilized for testing from the remaining subjects (i.e., 7).
| Training | Testing | ||||||
|---|---|---|---|---|---|---|---|
| Subject Folds | Ids | Mask Folds | Ids | Subject Folds | Ids | Mask Folds | Ids |
| 1 | 1, 2, and 3 | 1 | 2, 3, and 8 | 1 |
4 to 10 | 1 | 1,4,5,6,7,9,10 |
| 1, 2, and 3 | 2 | 4,5, and 9 | 4 to 10 | 2 | 1,2,3,6,7,8,10 | ||
| 1, 2, and 3 | 3 | 6, 7, and 10 | 4 to 10 | 3 | 1,2,3,4,5,8,9 | ||
2 |
4,5, and 6 | 1 | 2, 3, and 8 | 2 |
1 to 3 and 7 to 10 | 1 | 1,4,5,6,7,9,10 |
| 4,5, and 6 | 2 | 4,5, and 9 | 1 to 3 and 7 to 10 | 2 | 1,2,3,6,7,8,10 | ||
| 4,5, and 6 | 3 | 6, 7, and 10 | 1 to 3 and 7 to 10 | 3 | 1,2,3,4,5,8,9 | ||
3 |
7, 8, 9 and 10 | 1 | 2, 3, and 8 | 3 |
1 to 6 | 1 | 1,4,5,6,7,9,10 |
| 7, 8, 9 and 10 | 2 | 4,5, and 9 | 1 to 6 | 2 | 1,2,3,6,7,8,10 | ||
| 7, 8, 9 and 10 | 3 | 6, 7, and 10 | 1 to 6 | 3 | 1,2,3,4,5,8,9 | ||
The database can be downloaded from the following link.
Multispectral Latex Mask based Video Face Presentation Attack (MLFP) Database (46.89GB) (MD5: BF08F103164EB1E901A6C2AC8FC5F2E2, CRC: 0CA4190B)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for Multispectral Latex Mask based Video Face Presentation Attack (MLFP)"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper:
[1] A. Agarwal, D. Yadav, N. Kohli, R. Singh, M. Vatsa, and A. Noore. Face presentation attack with latex masks in multispectral videos. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 275–283, 2017.
Coming Soon...
Silicone Mask Attack Database (SMAD) consists of 65 videos of face biometric presentation attacks through real life silicone masks and 65 genuine face biometric access videos. The database is assembled to facilitate research efforts in building algorithms for unconstrained face presentation attack detection
The list of URLs is compiled in a text file.
- Text file containing the URLs (7KB)
(CRC32: 5068f528, MD5: 19ac5f9640032125e2084a9d23fb4d3c, SHA-1: 0cf73a281a6b309ee76fe155a7c7f385aaf3ce1e) - To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for Silicon Mask Attack Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - I. Manjani, S. Tariyal, M. Vatsa, R. Singh, A. Majumdar, Detecting Silicone Mask based Presentation Attack via Deep Dictionary Learning, IEEE Transactions on Information Forensics and Security, Volume 12, No. 7, pp. 1713-1723, 2017.
Disclaimer: The videos in the Silicone Mask Face Attack Database are downloaded from the internet. The time interval of spoof and genuine videos varies from 3 to 15 second and may differ from the original videos. Therefore, we are willing to share videos and their labels as used in our experiments. Please contact via e-mail for the same.
Face Recognition
The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. In this work, we explore possible bias in the domain of facial region localization. Being essential for all face detection and recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Since most existing face detection datasets lack suitable annotation for such analysis, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. We design an experimental setup to study the performance of four pre-trained face detectors utilizing the extensive annotations from F2LA. We observe a high disparity in detection accuracies across gender and skin-tone and draw detailed analysis for observed discrepancies. We further discuss the role of confounding factors beyond demography in face detection. The database can be downloaded from here.
Drone Surveillance of Faces, is a large-scale drone dataset intended to facilitate research for face recognition using drones.
Data has been captured at two outdoor locations: (i) at the ground level, where subjects are asked to walk in a park-like environment, and (ii) at the terrace of a building. For each location and surveillance scenario, data is captured twice: (i) during the morning and (ii) during the evening, before sunset.
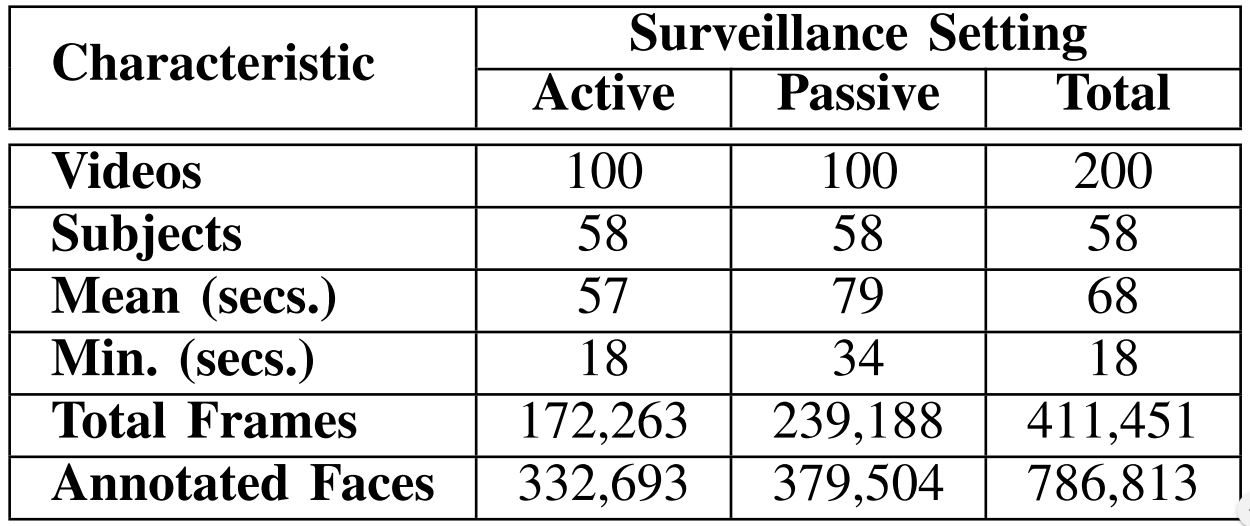
For each combination of location, surveillance use case, and time of capture, there exist 25 videos featuring 58 subjects. Each subject belongs to the age bracket of (18, 40) years, and each video contains subjects appearing in groups of 2-3. For a particular setting combination, one group appears in only one video. Since there exist eight combinations of location, surveillance scenario, and time of capture, each group of subjects occur in eight videos, thus resulting in a total of 200 videos. The subjects and pairings remain consistent across different settings.
The directory structure represents the combination of location, use case and time of capture.

Active Surveillance

Passive Surveillance

Dataset Challenges
We provide the ground truth annotations for each subject in each video, the high-quality gallery images of each subject and the recommended train-test splits.
Baseline Results-

Detection Baseline
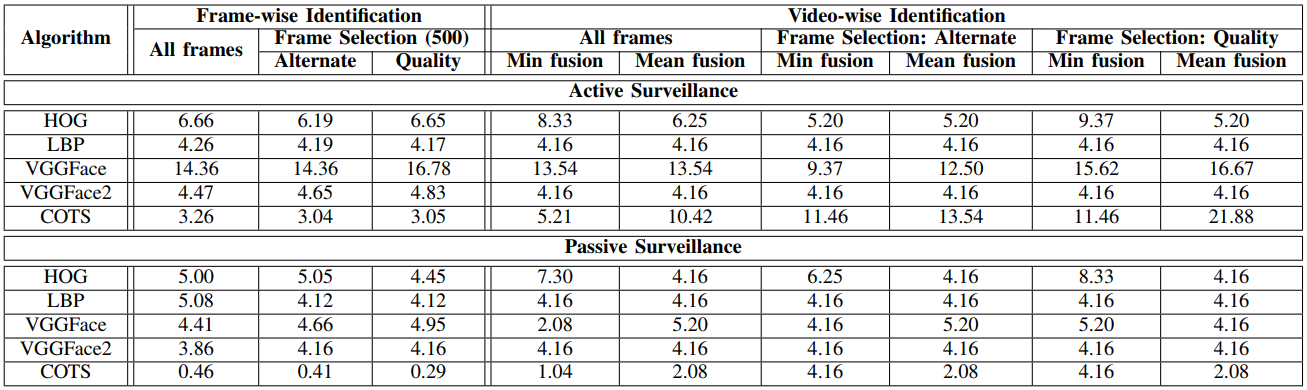
Recognition Baseline
The database can be downloaded from the following link.
DroneSURF Database (12.6 GB) (CRC-32: E1CE8891 , MD5: E9CEC01591E7ABB46FA880B52B1C8CF7 )
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for DroneSURF Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - I. Kalra, M. Singh, S. Nagpal, R. Singh, and M. Vatsa, DroneSURF: Benchmark Dataset for Drone-based Face Recognition, In IEEE International Conference on Automatic Face and Gesture Recognition, 2019.
Face recognition in surveillance sceanrios is an open research problem due to the challenges it poses in form of unconstrained pose, expression, illumination and distance. In order to deal with the above detailed issues depth data from 3D sensors could be used in concert with RGB face images for building robust face recognition system.
The KaspAROV Database consists of face images of 108 male and female subjects taken from videos collected from Microsoft Kinect version 1 and version 2 sensors in surveillance like conditions. Each subject appears in two videos taken in different sessions using both the Kinect sensors. KaspAROV dataset contains a total of 432 videos / 117,831 frames.
For Kinect version 1 and 2, RGB faces are available in png format and Depth face data is available in raw form in MAT files. For Kinect version 2 NIR face images are also available in raw form in MAT files. All the face images are available in 64x64 resolution.
Sample face images for two subjects from the KaspAROV RGBDI database captured using the Kinect v2 device. First two columns depict visible spectrum images, the next two columns corresponding depth images, and the final two columns represent NIR images.

Sample RGB-D frames. The first two columns contain frames captured using Kinect v1 device (from left to right: visible and depth) and the last three columns contain frames captured using the Kinect v2 device (from left to right: visible, depth, and NIR).
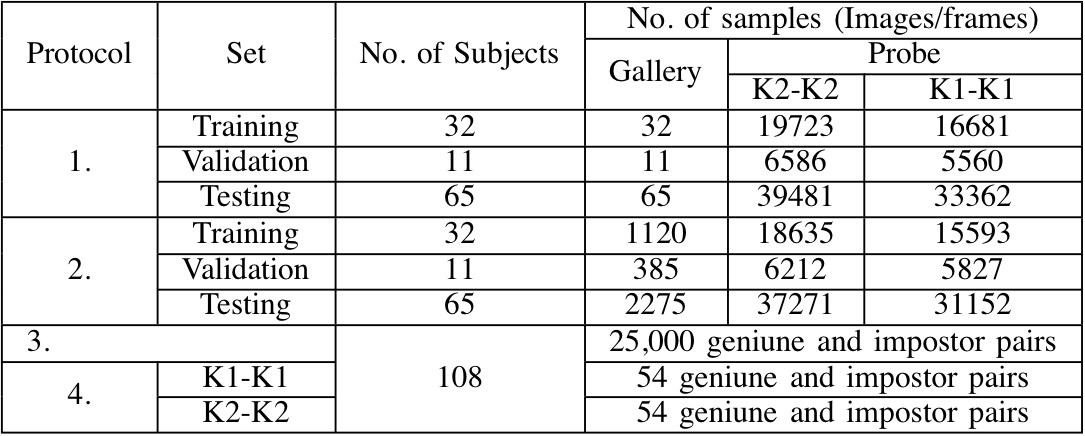
An overview of the experimental protocols defined on the KaspAROV database. 1. Single gallery identification, 2. Video based identification, 3. Image based verification, and 4. Video based verification. K1-K1: only Kinect v1 data, K2-K2: only Kinect v2 data, K2-K1+K2: Kinect v2 data as gallery and remaining 3 videos as probe, K2-K1: Kinect v2 data as gallery and only Kinect v1 data as probe.
The database can be downloaded from the following link.
KaspAROV Kinect Video Database (1.49 GB) (CRC-32: 5C89398D, MD5: BD7E3156F0F30EFDBF8A5A3ED7429F70)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for SmartPhone Fingerphoto Database V1 (ISPFDv1)"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - A. Chowdhury, S. Ghosh, R. Singh, and M. Vatsa, RGB-D Face Recognition via Learning-based Reconstruction, In Proceedings of IEEE International Conference on Biometrics: Theory, Applications and Systems, 2016.
- P. Chhokra, A. Chowdhury, G. Goswami, M. Vatsa, and R. Singh, "Unconstrained Kinect Video Face Database", Information Fusion, 2018 (Accepted).
Baseline Results
Single gallery Identification
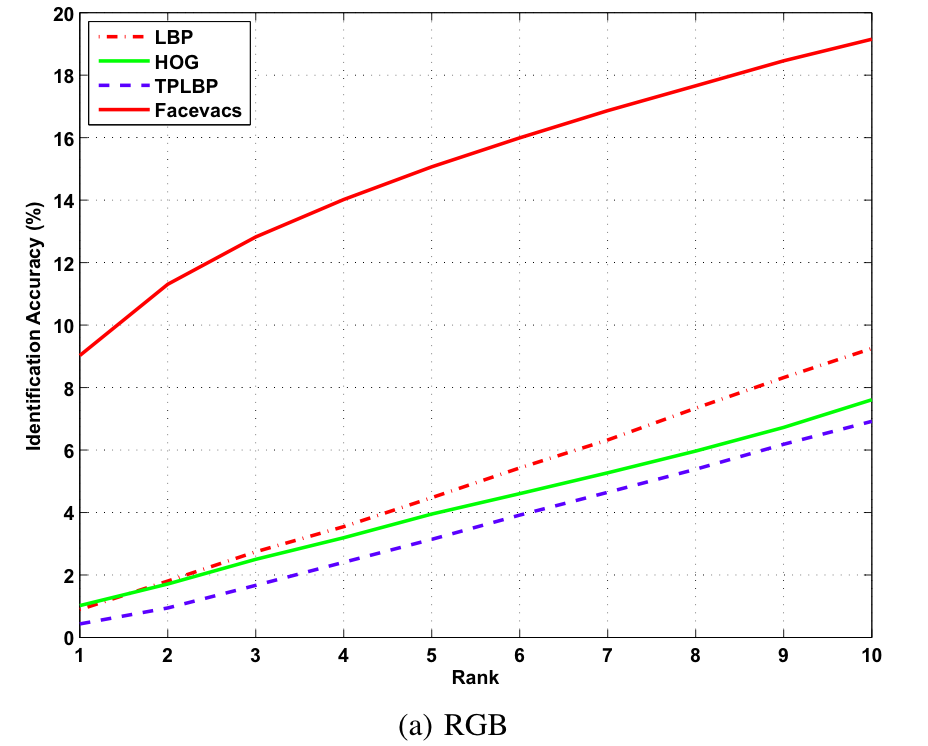
Baseline CMC curves for single gallery identification experiments on the proposed KaspAROV database using different algorithms and Kinect v1 data.
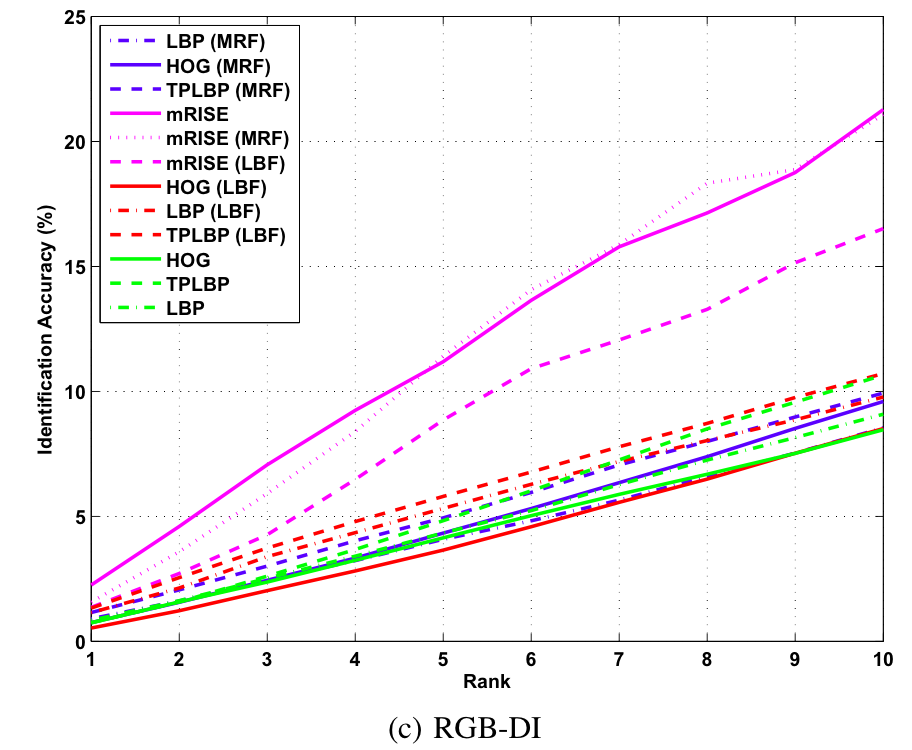
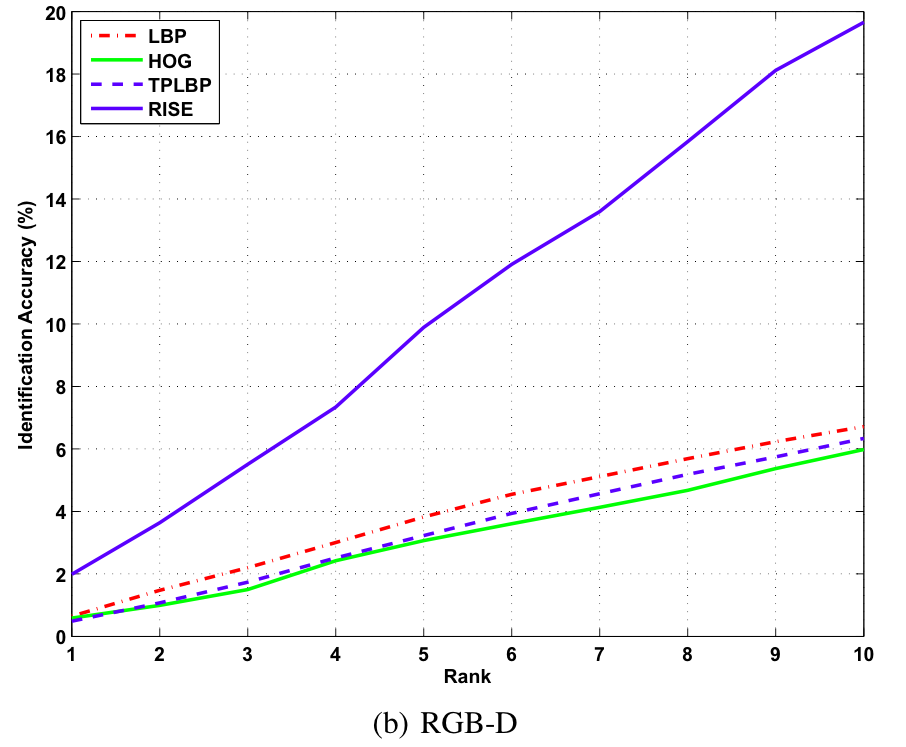
Baseline CMC curves for single gallery identification experiments on the proposed KaspAROV database using different algorithms and Kinect v2 data.
Image based Verification
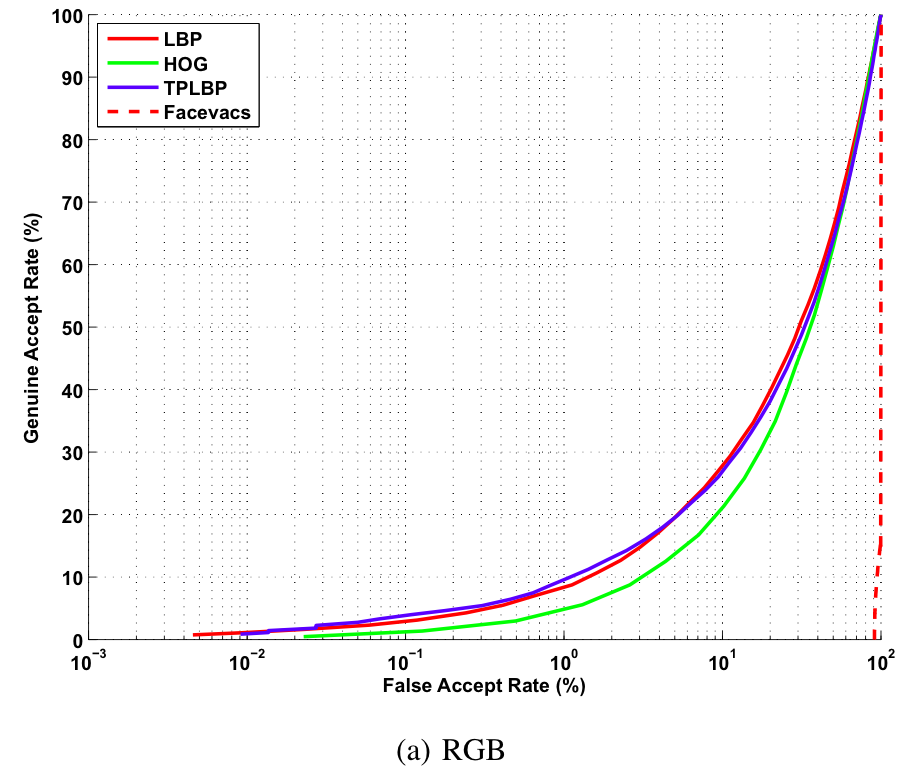
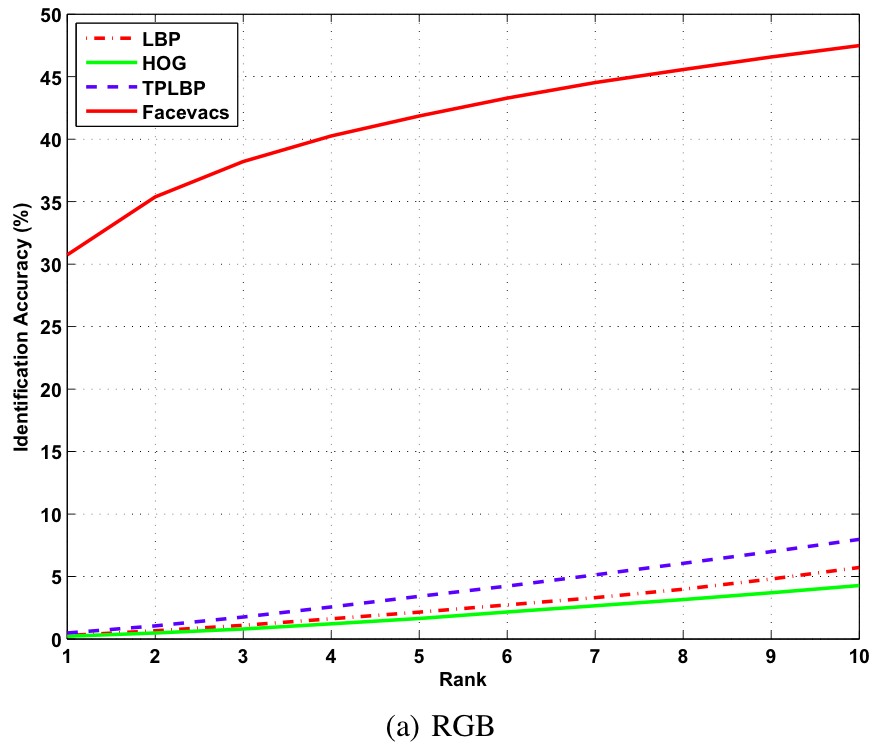
Baseline ROC curves for image based verification experiments on the proposed KaspAROV database using different algorithms and Kinect v1 data.
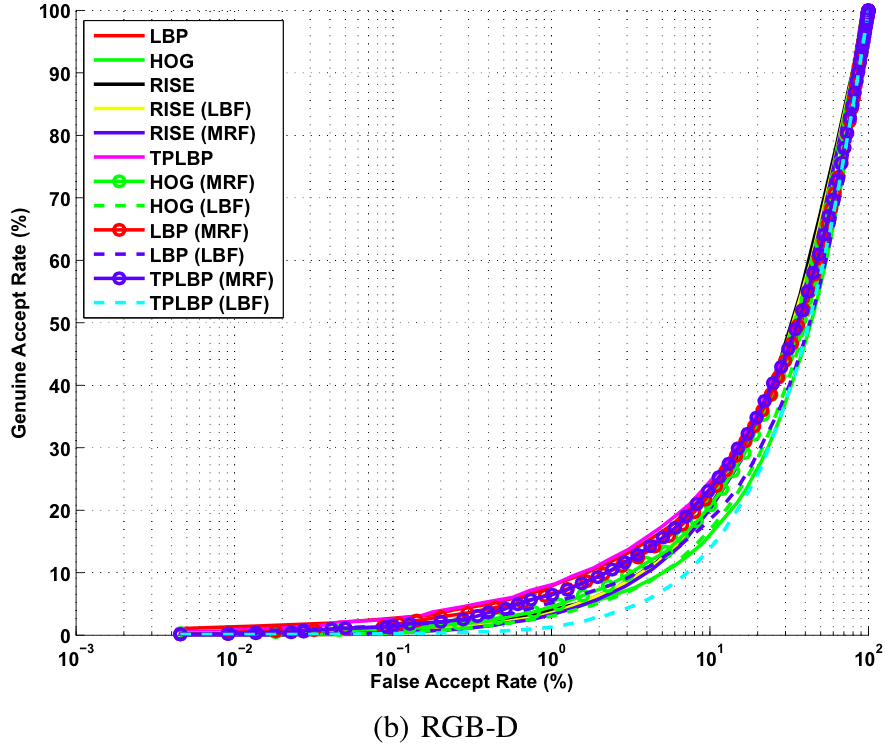

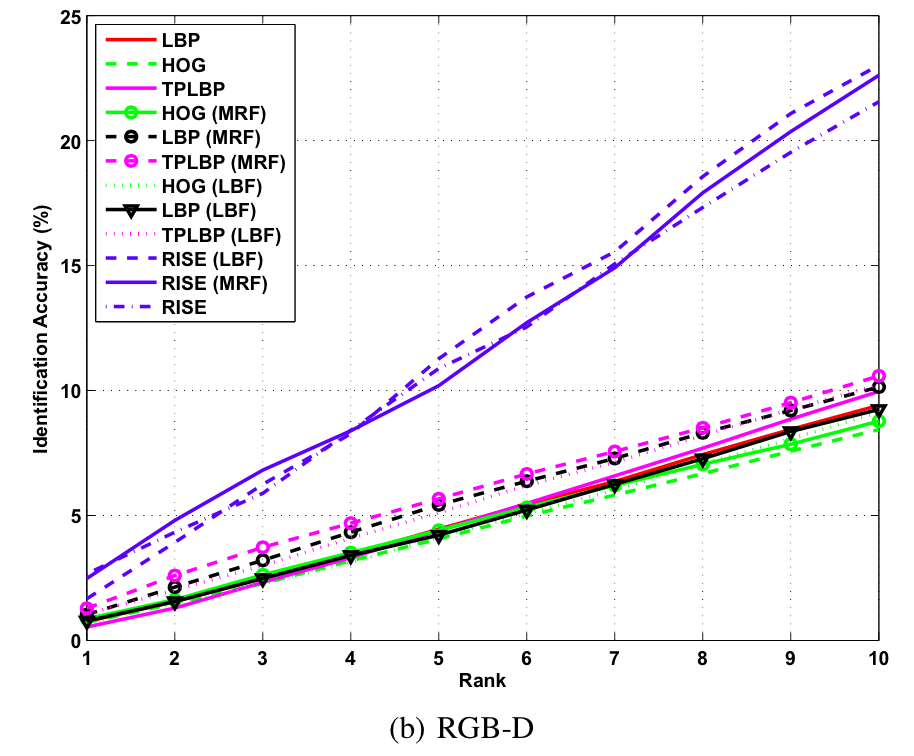
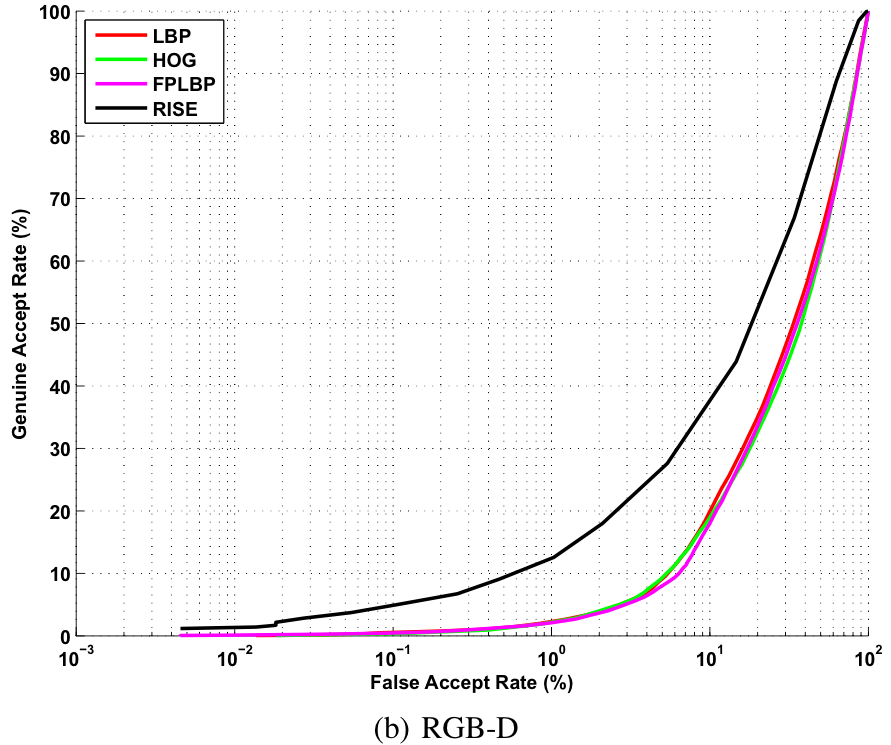
Baseline ROC curves for image based verification experiments on the proposed KaspAROV database using different algorithms and Kinect v2 data.
Video Based Verification
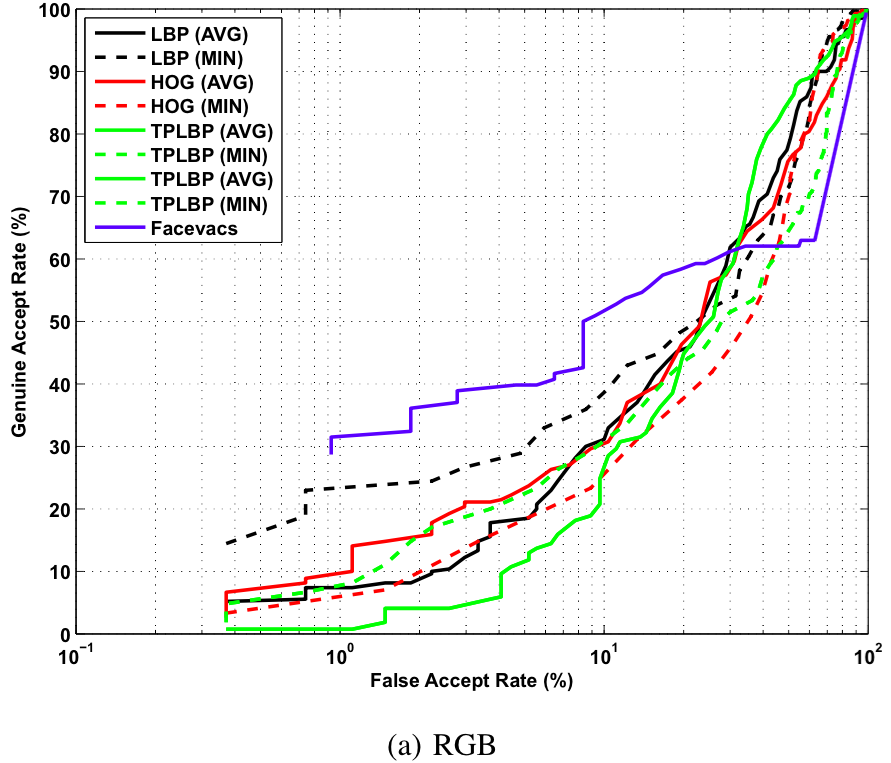
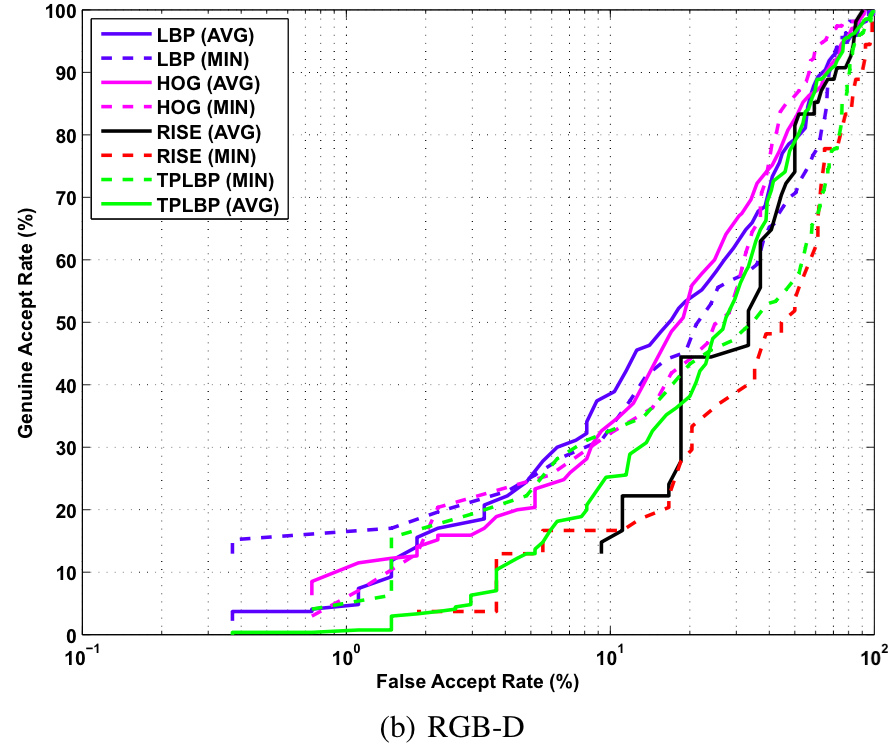
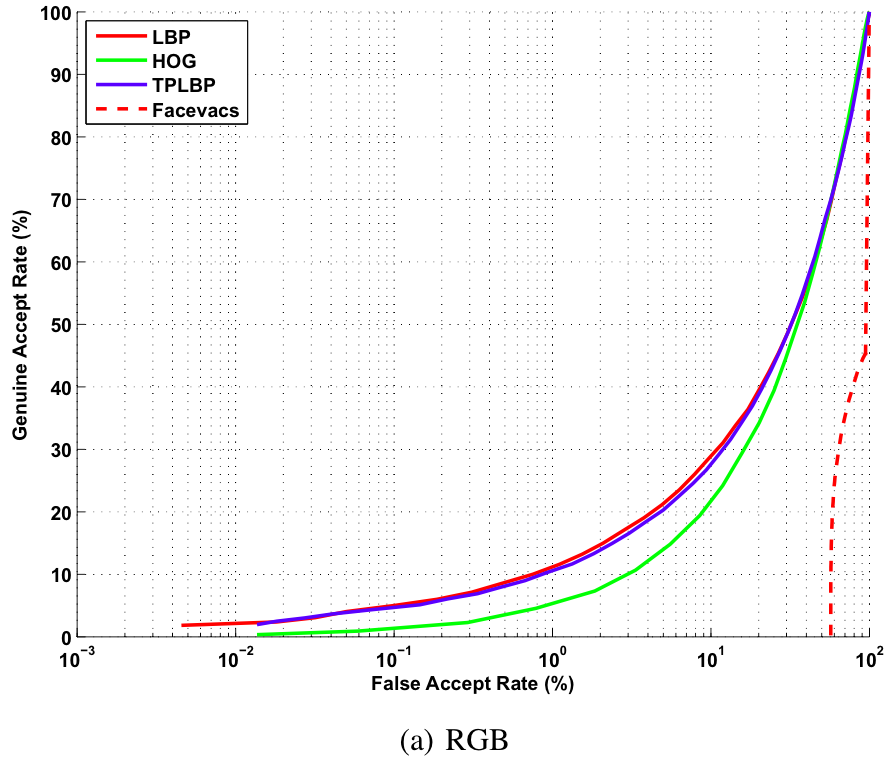
Baseline ROC curves for video based verification experiments on the proposed KaspAROV database using different algorithms and Kinect v1 data.
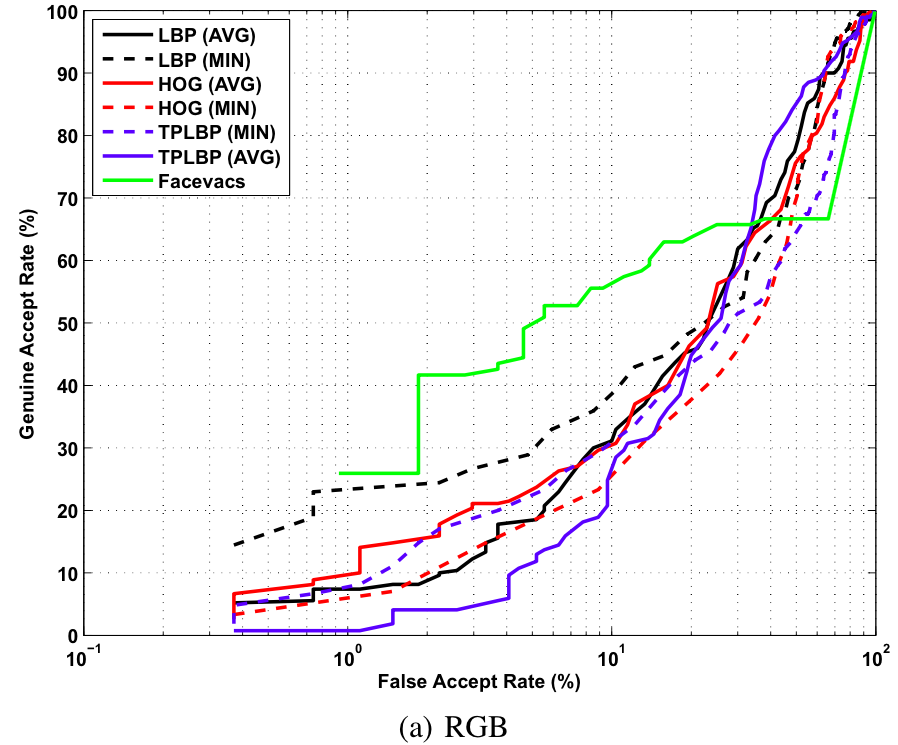
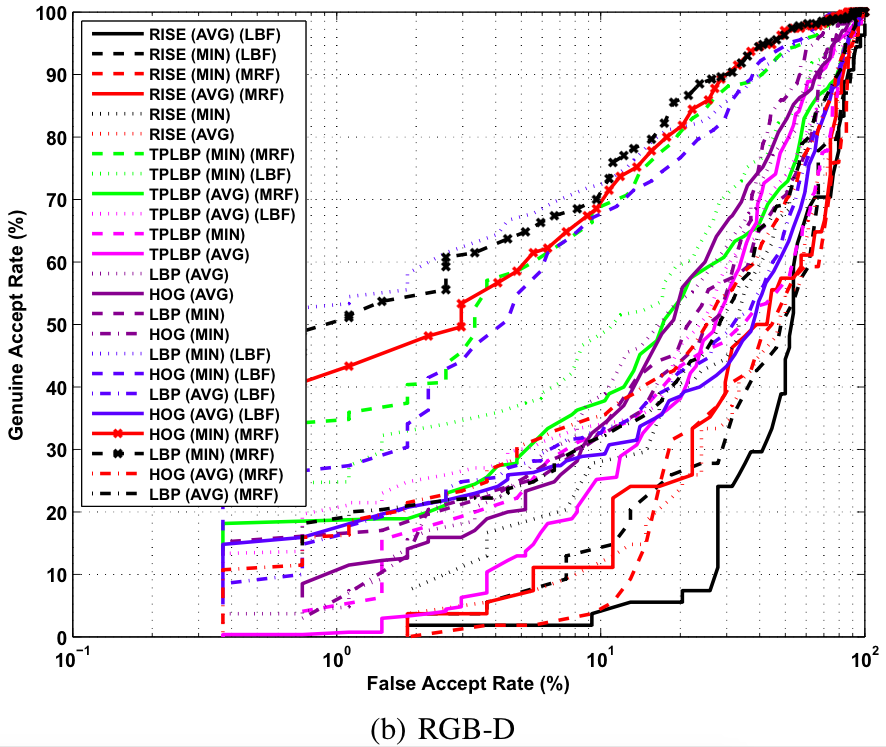
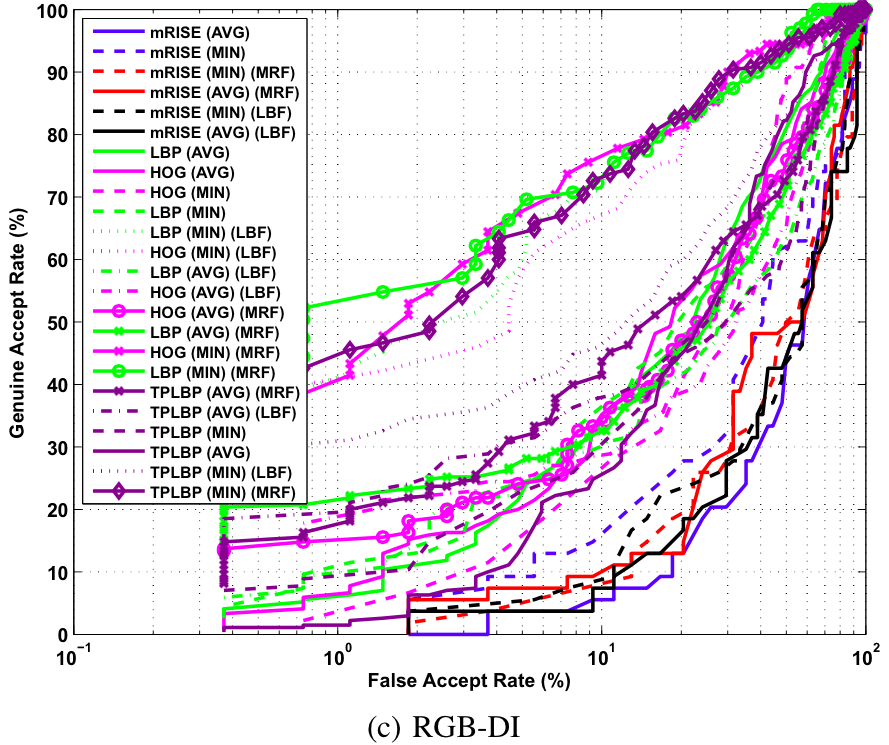
Baseline ROC curves for video based verification experiments on the proposed KaspAROV database using different algorithms and Kinect v2 data.
The database consists of 3529 sketches and digital face images pertaining to 150 individuals. Out of the 150 subjects, 52 are selected from the FGNET Aging Database, 82 are selected from IIIT-D Aging Database, and the remaining subjects are collected from the Internet. Due to license restrictions, we won't be able to share the images from the FG-Net dataset. Digital images and sketches pertaining to the remaining 98 subjects have been released.
The database can be downloaded from the following link:
Composite Sketch with Age variations (CSA) Database (18.7 MB) (CRC32: 2BD78738, MD5: EE776B95A20471A0EFF1A916A708B5E5)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for CSA database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - T. Chugh, M. Singh, S. Nagpal, R. Singh, and M. Vatsa, Transfer Learning based Evolutionary Algorithm for Composite Face Sketch Recognition, In IEEE Computer Vision and Pattern Recognition Workshops (CVPRW) on Biometrics, 2017.
- S. Nagpal, M. Singh, R. Singh, M. Vatsa, A. Noore, and A. Majumdar, Face Sketch Matching via Coupled Deep Transform Learning, International Conference on Computer Vision, 2017.
The DFW dataset consists of 1000 subjects and 11157 images. Pre-defined training and testing splits are provided, where 400 subjects form the training set, while the remaining 600 subjects form the test set. Each subject may contain normal, validation, disguised, and impersonator images. Nomenclature of the dataset is as follows:
- Subject normal images are named as xxx.jpg. For example: 0010.jpg
- Subject validation images follow xxx_a.jpg naming format. For example: 0010_a.jpg
- Disguised images are named as xxx_h_0xx.jpg. For example: 0010_h_001.jpg
- Impersonator images are named as xxx_I_0xx.jpg. For example: 0010_I_001.jpg
The database can be downloaded from the following link:
Disguised Faces in the Wild Database (DFW) (4.50 GB) (CRC-32:DC07476B, MD5:32821721C7239DC8B2CE34C96A21284B)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for DFW Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - M. Singh, R. Singh, M. Vatsa, N. Ratha, and R. Chellappa, Recognizing Disguised Faces in the Wild, IEEE Transactions on Biometrics, Behavior, and Identity Science, Volume 1, No. 2, Pages 97-108, 2019.
- V. Kushwaha, M. Singh, R. Singh, M. Vatsa, N. Ratha, and R. Chellappa, Disguised Faces in the Wild, IEEE International Conference on Computer Vision and Pattern Recognition Workshop on Disguised Faces in the Wild, 2018.
The KIVI database consists of video sequences of 503 individuals forming a total of 355 positive kin pairs from 211 families. For creating the proposed KIVI database, popular celebrity families are selected. The ground truth is annotated manually by validating the kinship information from the Internet. For each subject in the database, there is one corresponding video. The average video duration is 18.78 seconds with average frame rate of 26.79 frames per second (fps). The total number of still frames in the database is over 250,000. The database includes seven kin-relations. The database contains videos with variations in illumination, pose, occlusion, ethnicity, and expression collected from the Internet. The database has multi-ethnic kin pairs of Asian, Caucasian, and African-American ethnicity.

The database can be downloaded from the following link.
Kinship Video (KIVI) face database (40.6 KB) (CRC32: C46A9B71, MD5: 9CB19A900F8056C6950CCEB56C26198C)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for SmartPhone Fingerphoto Database V1 (ISPFDv1)"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - N. Kohli, D. Yadav, M. Vatsa, R. Singh and A. Noore, "Supervised Mixed Norm Autoencoder for Kinship Verification in Unconstrained Videos," in IEEE Transactions on Image Processing, 2018.
Existing face recognition algorithms achieve high recognition performance for frontal face images with good illumination and close proximity to the imaging device. However, most of the existing algorithms fail to perform equally well in surveillance scenarios, where videos are captured across varying resolutions and spectra. In surveillance settings, cameras are usually placed far away from the subjects, thereby resulting in variations across pose, illumination, occlusion, and resolution. Current video datasets used for face recognition are often captured in constrained environments, and thus fail to simulate the real world scenarios.

Statistics + Training / Testing Split:
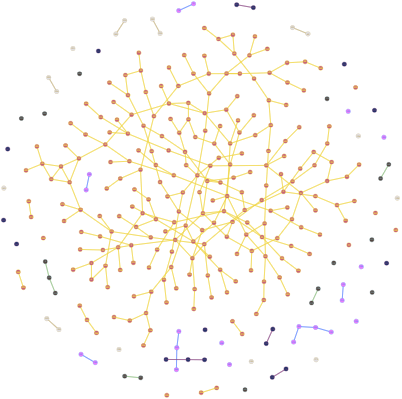
The division of data in this crowd scenario where multiple subjects are present in the same video and a subject has given more than one videos, the division of training and testing data is tricky. In order to ensure mutual exclusivity between the training and testing data, the entire dataset is modelled as a graph with various connected components, where a connected component corresponds to a group of people who gave a video together → directly or indirectly. Then one entire connected component either goes in the training set or in the testing set, thereby ensuring that no subject occurs both in the training and testing set. The visualed data can be seen below with 43 connected components.
Nomenclature and Dataset details:
The number of subjects in the training set is 200, while the number of subjects in the testing set is 52. All videos are named in the following format: 'Time_LocationID_VideoID_SubjectID1...SubjectIDn'. Here, time refers to the time of the day the video was captured and may take two values, N or D. LocationID corresponds to the location at which the video was captured. It can take one of four values: S1, S2, S3 or S4. Here S1 and S2 refer to the sessions recorded in the day-time locations, while S3 and S4 refer to sessions recorded in the night-time locations. VideoID corresponds to a unique ID given to each video of a location and SubjectID corresponds to a unique ID given to each subject. For example, consider the video name N_S4_V_28_67_0, where N corresponds to a night-time video and S4 denotes that the video was captured in the fourth location. V28 denotes that video’s unique ID and the remaining number(s) denote the subject IDs which are present in the video. Subject ID 0 corresponds to subjects belonging to the open-set. This nomenclature ensures that every video obtains a unique and informative name. The high resolution still images have been named as SubjectID 1, SubjectID 2 and SubjectID 3 for each subject.
The dataset also includes annotated frames containing a bounding box for every face in each frame (about 1.42 lakh faces), following the nomenclature described above. Along with the loose cropped face images, each subject’s three high resolution still images are also part of the release. A small section of non-overlapping videos acquired under the same setup are also provided as a training set for learning based experiments.
The database can be downloaded from the following link.
FaceSurv Database (4.71 GB) (CRC-32: D8285DB0 , MD5: 336CBD48A21CD3A0497397907EFB4ADD )
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for FaceSurv Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
Coming Soon...
The dataset contains 464 skull images, and is divided into two parts: (i) skull and digital face image pairs, and (ii) unlabeled supplementary skull images. The first component consists of pairs collected from real world examples of solved skull identification cases, while the second part contains unlabeled skull images.
The list of URLs is compiled in two text files along with a tool to download the images present at these URLs. The tool will download the images and store them at the specified location.
- Text file containing the URLs (7KB)
(CRC32: C06CBB6B, MD5: D5139942A307421D32936B16985BA97B, SHA-1: 4C6EA1AAAC16447EDA16CEF3FBABFA23D336ABA1) - Tool to download the images(11KB)
(CRC32: 2548A7C1, MD5: 79DF4CF8D12B724DCB6B54827C9C9738, SHA-1: 44731E292E05FFE683C2BB5BC1A67216ACADF2DC) - To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for IdentifyMe Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - S. Nagpal, M. Singh, A. Jain, R. Singh, M. Vatsa, and A. Noore, On Matching Skulls to Digital Face Images: A Preliminary Approach, In Proceedings of IEEE International Joint Conference on Biometrics, 2017.
Disclaimer:The images in the IdentifyMe database are downloaded from the internet and some of the images on different websites seem to have been taken down. Since it is extremely difficult to keep track of all the links, we are willing to share a mat file containing the normalized images and their labels as used in our experiments. Please contact via e-mail for the same.
Current research on matching sketches with digital face images has primarily focused on hand drawn sketches. However, law enforcement agencies are now using software tools to generate composite sketches. In this paper, we propose a face recognition algorithm to match composite sketches with digital face images. The contribution of this research is three fold: (1) proposing feature extraction and matching algorithm using visual saliency and combination of texture features, (2) incorporating attributes for re-ordering the ranked list, and (3) utilizing multiple experts such as multiple composite sketch generation tools or artists for improving the matching performance. The results computed on the extended PRIP database show that the proposed algorithm improves the state-of-art in matching composite sketch and digital face images and yields the rank 50 identification accuracy of 81.3%.
- Text file containing the URLs (7KB)
(CRC32: C06CBB6B, MD5: D5139942A307421D32936B16985BA97B, SHA-1: 4C6EA1AAAC16447EDA16CEF3FBABFA23D336ABA1) - Tool to download the images(11KB)
(CRC32: 2548A7C1, MD5: 79DF4CF8D12B724DCB6B54827C9C9738, SHA-1: 44731E292E05FFE683C2BB5BC1A67216ACADF2DC) - To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for IdentifyMe Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - S. Nagpal, M. Singh, A. Jain, R. Singh, M. Vatsa, and A. Noore, On Matching Skulls to Digital Face Images: A Preliminary Approach, In Proceedings of IEEE International Joint Conference on Biometrics, 2017.
Disclaimer:The images in the IdentifyMe database are downloaded from the internet and some of the images on different websites seem to have been taken down. Since it is extremely difficult to keep track of all the links, we are willing to share a mat file containing the normalized images and their labels as used in our experiments. Please contact via e-mail for the same.
Face recognition algorithms generally utilize 2D images for feature extraction and matching. To achieve higher resilience towards covariates such as expression, illumination and pose, 3D face recognition algorithms are developed. While it is highly challenging to use specialized 3D sensors due to high cost, RGB-D images can be captured by low cost sensors such as Kinect. This research introduces a novel face recognition algorithm using RGB-D images. The proposed algorithm computes a descriptor based on the entropy of RGB-D faces along with the saliency feature obtained from a 2D face. Geometric facial attributes are also extracted from the depth image and face recognition is performed by fusing both the descriptor and attribute match scores. The experimental results indicate that the proposed algorithm achieves high face recognition accuracy on RGB-D images obtained using Kinect compared to existing 2D and 3D approaches.

The database can be downloaded from the following link.
IIIT-D Kinect RGB-D Face Database (377MB) (CRC32: 7DFAF27E, MD5: 817AF873A0E9BBF7960BB64D07AE34F5, SHA-1: 95E5926513CFD796A30E82DC9ADA1B8FCFE23CD6)
- To obtain the password for the compressed file, kindly take a print out of the license agreement fill it up and send the scanned copy to databases@iab-rubric.org with the subject line "License agreement for IIIT-D Kinect RGBD Face Database".
As soon as we obtain the signed license agreement in scanned form, we would provide you with the access to our database.
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following papers:
- G. Goswami, M. Vatsa, and R. Singh, RGB-D Face Recognition with Texture and Attribute Features, IEEE Transactions on Information Forensics and Security, 2014.
- G. Goswami, S. Bharadwaj, M. Vatsa, and R. Singh, On RGB-D Face Recognition using Kinect, International Conference on Biometrics: Theory, Applications and Systems, 2013.
Face verification, though an easy task for humans, is a long-standing open research area. This is largely due to the challenging covariates, such as disguise and aging, which make it very hard to accurately verify the identity of a person. This paper investigates human and machine performance for recognizing/verifying disguised faces. Performance is also evaluated under familiarity and match/mismatch with the ethnicity of observers. The findings of this study are used to develop an automated algorithm to verify the faces presented under disguise variations. We use automatically localized feature descriptors which can identify disguised face patches and account for this information to achieve improved matching accuracy.

We also explore the feasibility of face verification under disguise variations using multi-spectrum (visible and thermal) face images. Our framework classifies the local facial regions of both visible and thermal face images into biometric (regions without disguise) and non-biometric (regions with disguise) classes. The biometric patches are then used for facial feature extraction and matching. The experimental results suggest that the proposed framework improves the performance compared to existing algorithms. We also provide human performace evaulation for matching disguised face. However there is a need for more research to address this important covariate.
We prepared a dataset containing images pertaining to 75 subjects with different kinds of disguise variations. The version 1 of the dataset consists of images captured in visible spectrum. It is named as IIIT-Delhi Disguise Version 1 face database (ID V1). The IIITD In and Beyond Visible Spectrum Disguise database (I2BVSD)consists of face images captured in visible as well as thermal spectrum. Thus, ID V1 is a subset of I2BVSD.
Dataset
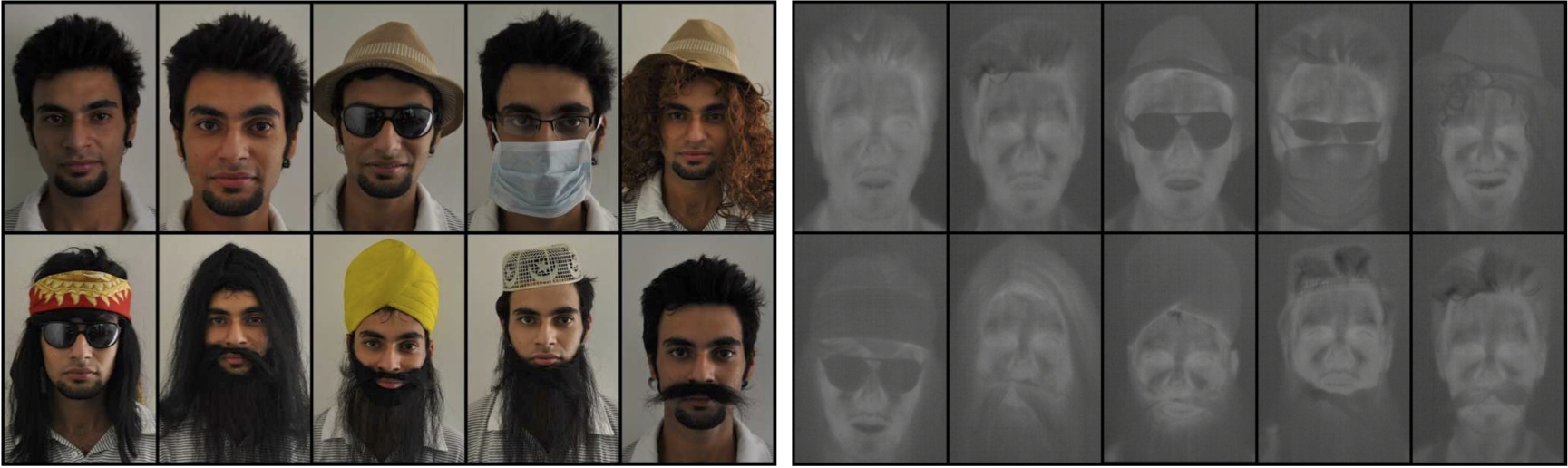
Fig 2. Sample images from the I2BVSD database (left) corresponding images captured in visible spectrum, and (right) contains images acquired in thermal spectrum.
- IIIT-Delhi Disguise Version 1 face database (ID V1):[681 visible spectrum images]
- Raw version (2.9GB) (CRC32: 17596FBD, MD5: AE9C4A5B4121234B1B96789F36A7DF60, SHA-1: 1FE976E2CD2FCE0C013BB2197E3B13C3D77E5610)
- Cropped version (11MB) (CRC32: 5F703418, MD5: 91C3D309A1003DFCBD927BAD1AD52127, SHA-1: 831260B1058E179D849C4C0C22F51F1637F52CA)
- IIITD In and Beyond Visible Spectrum Disguise database (I2BVSD): [681 images in visible and thermal spectrum each]
- Raw version part 1 (2.9GB) (CRC32: 17596FBD, MD5: AE9C4A5B4121234B1B96789F36A7DF60, SHA-1: 1FE976E2CD2FCE0C013BB2197E3B13C3D77E5610)
- Raw version part 2 (79.2MB) (CRC32: 2B6546CD, MD5: D938ECCF765FFAD81A576BCB1C7A7EC3, SHA-1: 6609AB4AC01D339058005514AB78636B94C923BB)
- Cropped version part 1 (11MB) (CRC32: 5F703418, MD5: 91C3D309A1003DFCBD927BAD1AD52127, SHA-1: 831260B1058E179D849C4C0C22F51F1637F52CA)
- Cropped version part 2 (11MB) (CRC32: 0D72B44E, MD5: AE621B624D9EC7E6EF7A6042C5A249B9, SHA-1: FDDC2DDB56061C72C1D30E555AA82CA2466170CE)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for IIIT-D Disguise Face Database".
As soon as we obtain the signed license agreement in scanned form, we would provide you with the access to our database.
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following papers:
Publication
- T. I. Dhamecha, R. Singh, M. Vatsa, and A. Kumar, Recognizing Disguised Faces: Human and Machine Evaluation, PLoS ONE, 9(7): e99212, 2014.
- T. I. Dhamecha, A. Nigam, R. Singh, and M. Vatsa Disguise Detection and Face Recognition in Visible and Thermal Spectrums, In proceedings of International Conference on Biometrics, 2013 (Poster)
- Text file containing the URLs (31 KB)
(CRC32: D66DD59F, MD5: 63A4E41429A85F86741630339955D26B, SHA-1: B86B23DC03239766100861B818D9A0B3265237FA) - To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for IIIT-Delhi's WhoIsIt Database"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - M. Singh, S. Nagpal, R. Singh, and M. Vatsa, On Recognizing Face Images with Weight and Age Variations, IEEE Access, vol.2, pp.822,830, 2014.
- S. Nagpal, M. Singh, R. Singh, and M. Vatsa, Regularized Deep Learning for Face Recognition with Weight Variations",IEEE Access, 2015.
Disclaimer:The images in the extendedWhoIsIt database are downloaded from the internet and some of the images on different websites seem to have been taken down. Since it is extremely difficult to keep track of all the links, we are willing to share a mat file containing the normalized images and their labels as used in our experiments. Please contact via e-mail for the same.
IIIT-Delhi sketch database consist of three different types of sketches, namely, viewed, semi-forensic, and forensic sketches. Each user in the database has a sketch and a corresponding digital photograph. It introduces semi-forensic sketches that are drawn based on the memory of sketch artist to act as an intermediate representation between viewed and forensic sketches.
For more information please visit this page.
Disclaimer: This database consists of images collected from the internet. These forensic sketch-digital image pairs are collected in same spirit and understanding as the PubFig dataset and the Labeled Faces in the Wild (LFW) dataset. Therefore, we are sharing the direct link to the face images. Researchers can use this database but are not encouraged to publish any images from the database due to privacy reasons. Copyright of these images are with the original creators.
The database can be downloaded from the following link.
- IIIT-D Sketch Database (670MB)
(MD5: c814313ca2f98e829828769e91d736a5) - Read Me
- To obtain the password for the compressed file, kindly take a print out of the license agreement, fill it up and send the scanned copy to databases@iab-rubric.org. with the subject line "License agreement for IIIT-D Sketch Database".
As soon as we obtain the signed license agreement in scanned form, we would provide you with the access to our database.
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further. - H.S. Bhatt, S. Bharadwaj, R. Singh, and M. Vatsa, Memetically Optimized MCWLD for Matching Sketches with Digital Face Images, IEEE Transactions on Information Forensics and Security, Vol. 5, No. 5, pp. 1522-1535, 2012.
The plastic surgery face database is a real world database that contains 1800 pre and post surgery images pertaining to 900 subjects. For each individual, there are two frontal face images with proper illumination and neutral expression: the first is taken before surgery and the second is taken after surgery. The database contains 519 image pairs corresponding to local surgeries and 381 cases of global surgery (e.g., skin peeling and face lift). The details of the database and performance evaluation of several well known face recognition algorithms is available in the paper mentioned below.
The list of URLs is compiled in a text file along with a tool to download the images present at these URLs. The tool will download the images and store them at the specified location.
- Text file containing the URLs (7KB)
(CRC32: D132C4A2, MD5: 0FBE3041D95FEE000CAF263048B52480, SHA-1: 325AAED6F31E4AE1471DE44F91A9BC2B63B0AAFD) - Tool to download the images (11KB)
(CRC32: 2548A7C1, MD5: 79DF4CF8D12B724DCB6B54827C9C9738, SHA-1: 44731E292E05FFE683C2BB5BC1A67216ACADF2DC) - To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for Plastic Surgery Face Database".
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - R. Singh, M. Vatsa, H.S. Bhatt, S. Bharadwaj, A. Noore and S.S. Nooreyezdan, Plastic Surgery: A New Dimension to Face Recognition, In IEEE Transaction on Information Forensics and Security, Vol. 5, No. 3, pp. 441-448, 2010.
Disclaimer: The images in the plastic surgery database are downloaded from the internet and some of the subjects appear on different websites under different surgery labels. Therefore, this database may have some repetition of subjects across different types of surgeries. We have figured out multiple cases with such inconsistencies and provided an errata. If you come across some other cases as well, kindly report it to us.
Please find the text file of errata. The images seperated by comma(,) represent the redundant entries in the database.
Look Alike face database consists of images pertaining to 50 well known personalities (from western, eastern, and asian origins) and their look-alikes. Each subject/class has five genuine images (total 50 x 5 genuine cases) and five look-alike images (total 50 x 5 look-alikes). To obtain the database, email the duly filled license agreement, to databases@iab-rubric.org with the subject line "License agreement for Look Alike Face Database".
Database can be downloaded from here.
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper:
- H. Lamba, A. Sarkar, M. Vatsa, and R. Singh, Face Recognition for Look-Alikes: A Preliminary Study, In Proceedings of International Joint Conference on Biometrics, 2011.
Other
Indian Masked faces in the wild Database is collected into three sets:(i) Indian Celebrity, (ii) Instagram and (iii) Indian Crowd. The Indian Celebrity contains 40 Indian celebrities with 435 images, including Bollywood actors/actresses, television stars, sports personalities, and politicians. The Instagram set contains 377 images of 40 subjects downloaded from Instagram. We collected masked and non-masked images of Indian people with a public profile. The Indian Crowd set is collected from the common people who volunteered to contribute to the dataset. This set contains 120 subjects with 562 images. All the Images are collected in both constrained and unconstrained environments with variation in pose, illumination, background and masks worn by the people.
Due to privacy issues we will not be releasing the Instagram set. The database can be downloaded from the following link:
IMFW database (540 MB) (CRC32:1449f868 , MD5:3eee0446e471f4e5b237fd0f5597f28a)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for Indian Masked Faces In The Wild"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - S. Mishra, P. Majumdar, R. Singh, and M. Vatsa, "Indian Masked Faces in the Wild Dataset," in IEEE International Conference on Image Processing, 2021.
We have proposed the smart 2D video-based face presentation attack (i.e., replay attack) using image intensity transforms. The database contains the real and attack videos of 50 subjects. The real part of the database is taken from a high-quality subset of CASIA-FASD database. The real videos are captured using a high-quality camera with 1, 280 × 720 resolution. The attack dataset consists of five different subsets: one being the normal attack set and four are grouped under Image Transformation attack. In order to perform the attack, we have used the android phone with full HD display and high-quality USB camera with resolution 1, 920 × 1, 080. In place of using the attack videos of CASIA-FASD database, we have collected the attack videos to keep the device and other environmental factors consistent while capturing different sets of attack videos. The attack videos in this research can be broadly divided into two categories: (i) input transformation-based and (ii) screen brightness based.
The directory structure of smart 2D presentation attack database (Smart2D-PAD) and protocol for evaluation:
- For real videos, please refer CASIA-FASD database. The videos of the first 20 subjects are used for training and the remaining 30 for testing.
- Normal Attack (Set A): It contains videos of 50 subjects. The videos of the first 20 subjects (01-20) are used for training the classifier, whereas, the videos of remaining subjects (21-50) are used for evaluation.
- Set B, Set C, and Set D: It only contains the videos of testing subjects (21-50). The PAD trained on the normal attack (Set A) is used on these sets for presentation attack detection.
- SSet E: It refers to the videos collected in low brightness of the attacking medium. It only contains videos of testing subjects (21-50). Set A refers to the high brightness videos. The PAD trained on the normal attack (Set A) is used on these sets for presentation attack detection.
The database can be downloaded from the following link.
Smart2D-PAD (2.29 GB)
- To obtain the password for the compressed file, email the duly filled license agreement to databases@iab-rubric.org with the subject line "License agreement for SmartPhone Fingerphoto Database V1 (ISPFDv1)"
NOTE: The license agreement has to be signed by someone having the legal authority to sign on behalf of the institute, such as the head of the institution or registrar. If a license agreement is signed by someone else, it will not be processed further.
This database is available only for research and educational purpose and not for any commercial use. If you use the database in any publications or reports, you must refer to the following paper: - A. Agarwal, A. Sehwag, M. Vatsa, and R. Singh, Deceiving Face Presentation Attack Detection via Image Transforms, In IEEE International Conference on Multimedia Big Data (BigMM), 2019.
Coming Soon.
The ToonSet is a face-toon paired dataset. The dataset consists of a total of 60,000 original face images and their corresponding toon avatar images. 23,000 face images from FFHQ dataset are borrowed. These images are then transformed into toon avatars using toonme.com. Each face image is of size 512x512. Each face image was paired with its toon avatar and can be utilized for the target task. The database can be downloaded from here.