BhashaBluff: A Dataset and Benchmark for Detecting Bilingual, Noisy, Compressed Deepfakes and Synthetic Audios
Abstract
Robust detection methods are essential to address the growing threat of audio deepfakes and synthetic media, which are increasingly appearing in complex, real-world conditions. Existing research has primarily focused on clean, single-language audio, overlooking critical challenges like bilingualism, background noise, and various forms of codec compression. This paper introduces the BhashaBluff dataset, with approximately 2,500 hours of audio data and over 3.8 million samples generated using 21 distinct methods. Its key innovation lies in its extensive variability across three critical dimensions: (i) bilingualism, which encompasses Hindi and English deepfakes as well as code-mixed speech; (ii) noise, with samples corrupted by four distinct environmental noise types; and (iii) compression, incorporating seven neural compression techniques to simulate real-world artifacts. Benchmark evaluations using state-of-the-art models show substantial performance degradation when faced with these challenging conditions, revealing the limited generalizability of current methods and highlighting the urgent need for more adaptive and robust algorithms. BhashaBluff serves as a crucial benchmark for developing next-generation detection systems that are effective in diverse, noisy, and compressed audio environments. The BhashaBluff dataset, along with our evaluation benchmarks, will be made publicly available for academic research to encourage further development in this domain.
Research Questions
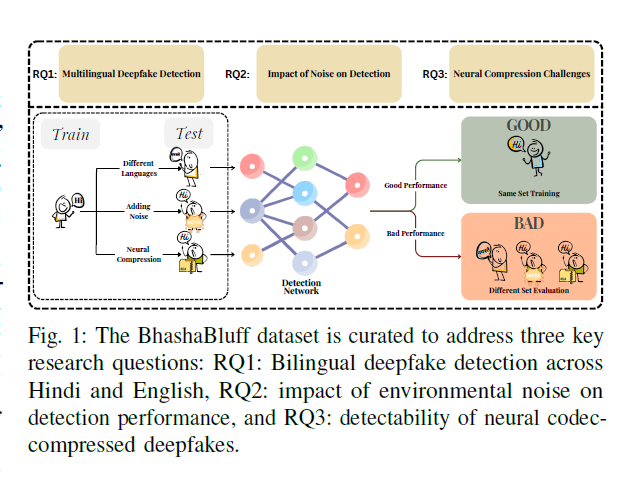
Dataset Design
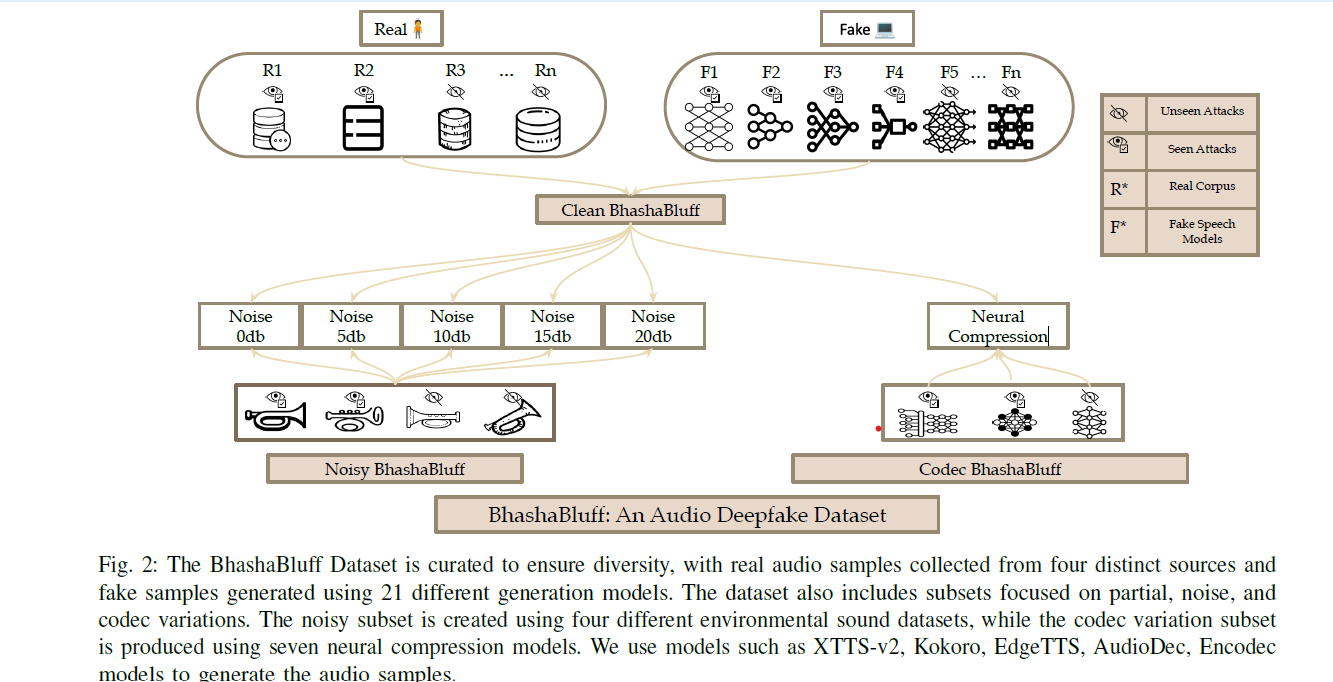
Comparison With Existing Dataset
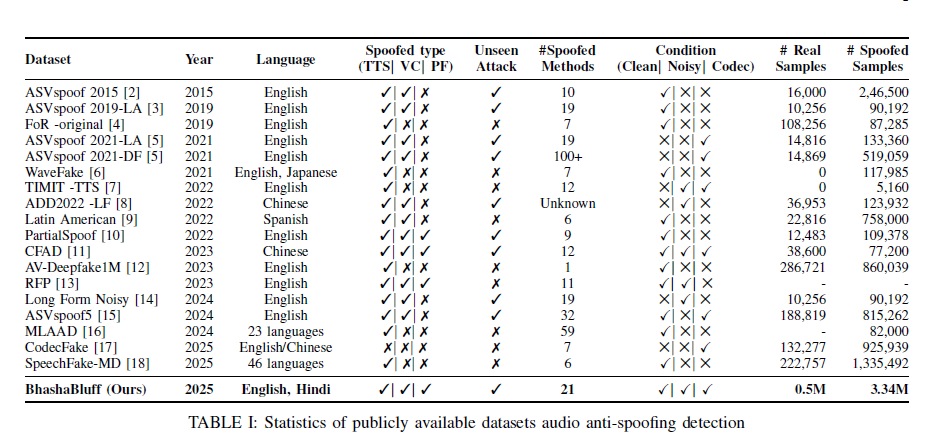
Dataset Statistics
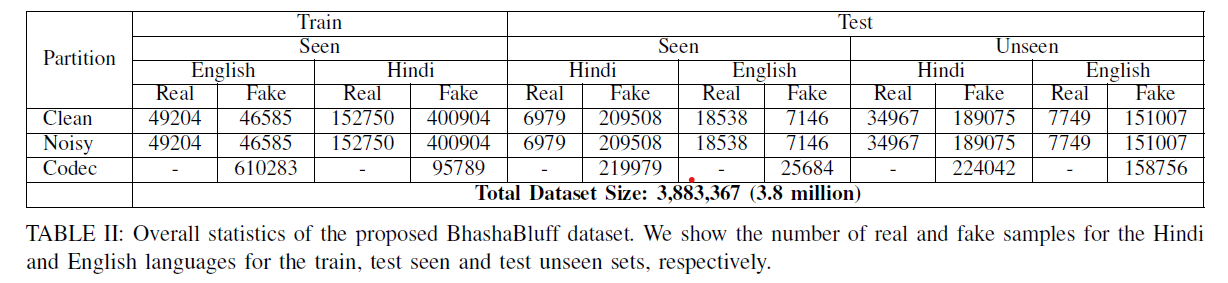
Sample Dataset
The subset of the dataset is available on this link. We have randomly created a subset of approximately 5000 audio samples across all partitions.
Complete Dataset
-
To obtain access to the dataset, please email the duly filled license agreement to databases@iab-rubric.org with the subject line "Licence agreement for BhashaBluff dataset".
-
NOTE: The license agreement must be signed by someone with the legal authority to sign on behalf of the institute, such as the head of the institution or the registrar. If a license agreement is signed by someone other than the intended recipient, it will not be processed further.