Audio-Bench: Unified ASR and TTS Evaluation Framework across Indian Languages

Introduction
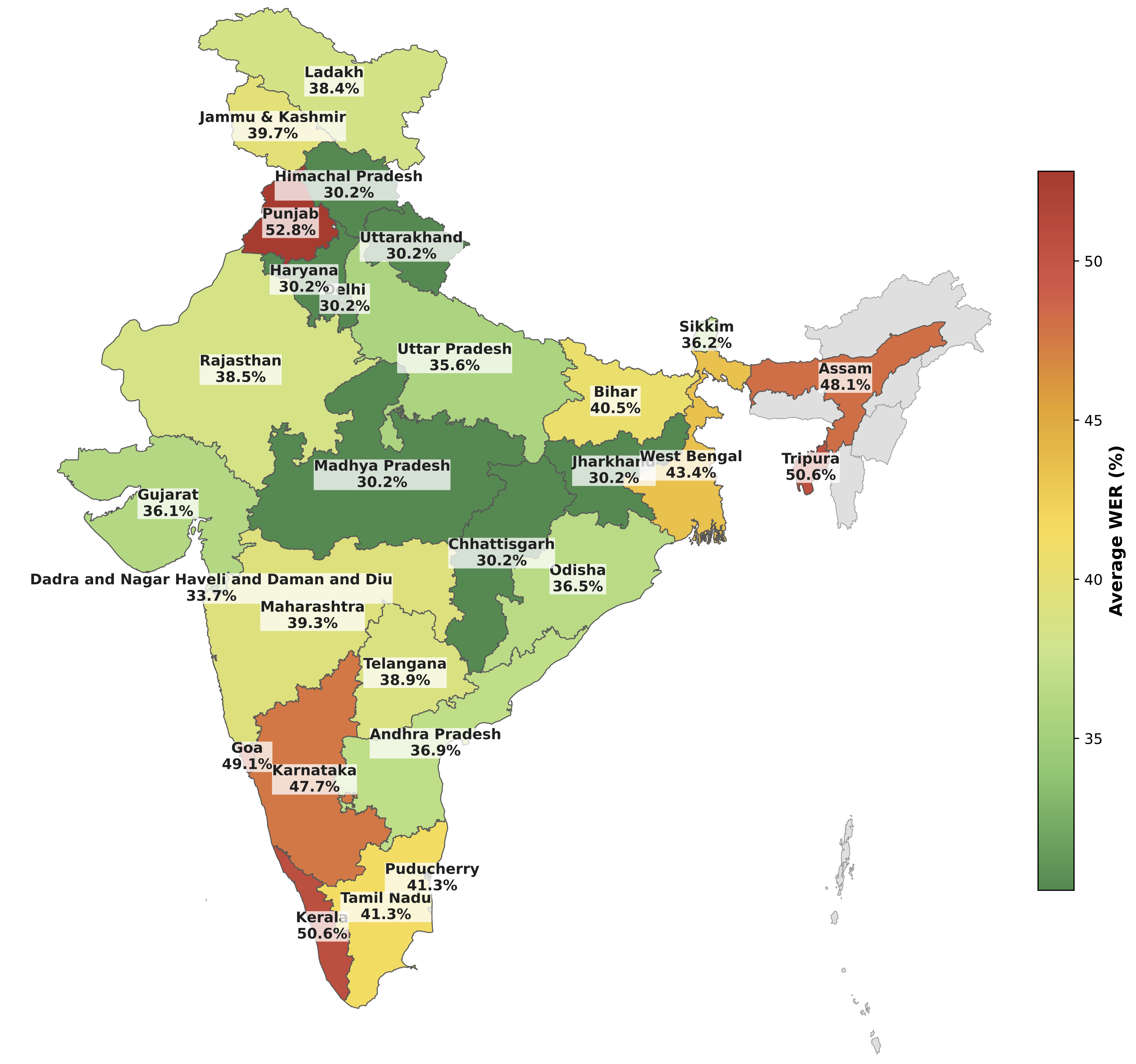
Evaluation of speech systems for Indian languages remains severely fragmented. Models are benchmarked on disjoint datasets with inconsistent preprocessing and metrics, making reproducibility and fair comparison nearly impossible. We address this with Audio-Bench, a modular, plug-and-play framework analogous to HuggingFace Evaluate where any model checkpoint and dataset can be registered through a standardized interface without modifying the core pipeline. Evaluating ten open-source ASR and TTS models across seven corpora spanning 22 Indian languages and Indian-accented English, Audio-Bench highlights what single-dataset, single-metric benchmarking conceals: parameter scaling does not guarantee cross-language robustness; perceptual naturalness and objective intelligibility diverge markedly in TTS; and domain sensitivity remains a critical vulnerability across all ASR architectures.
GitHub
Coming soon.
Citation
@misc{dutta_audiobench,
title={Audio-Bench: Unified ASR and TTS Evaluation Framework across Indian Languages},
author={Dutta, Bikash and Gahankari, Siddhant and Kumar, Abhinav and Modugu, Siddarth and Kapoor, Shalini and Vatsa, Mayank and Singh, Richa},
}